Databricks Berlin User Group: A Recap and a Surprise
Last week I gave my first technical talk in years at the Databricks Berlin User Group. I want to write down a few things while they are still fresh, because they were not what I expected.
The talk
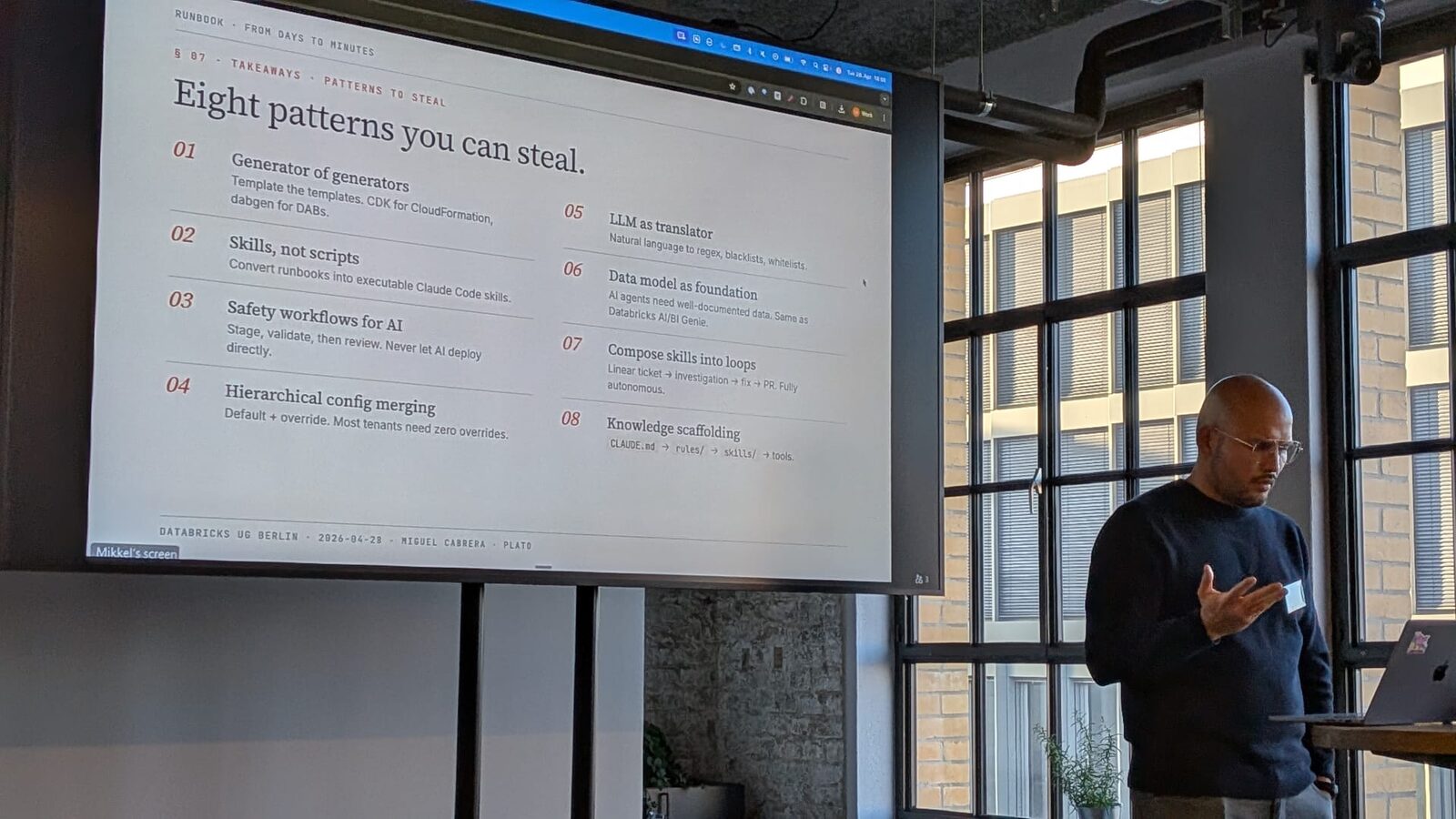
The premise: at Plato we ship 25+ ML algorithms across 50+ wholesale-distributor tenants, and we do it without hand-rolling deployments. The plumbing under that is Databricks Asset Bundles (recently rebranded to Declarative Automation Bundles, or DABs) plus a small generator we wrote called dabgen, plus a Claude Code skill that drives the onboarding end-to-end.
Title was “From Days to Minutes: How We Taught an AI to Onboard 50+ Tenants on our AI Features.” Slides are on Speaker Deck.
It went well. The food was great. The conversations after were better.
The surprise
I had built the talk assuming most of the room was already using DABs in production, and most engineers in the room were using AI coding assistants daily. The whole framing was “advanced workflow tricks.” Stuff like: how to layer overrides cleanly, where to draw the line between Jinja templates and runtime config, what a CI/CD pipeline looks like when an AI is the one writing your tenant configs.
Turns out fewer people than I thought were actually using DABs in production. Same story with the AI coding wave (Claude Code, Codex, Cursor, the whole stack). I was talking like these were table stakes. They are not, yet.
That changed how I read my own talk afterwards. For a lot of the audience, the value was not in the specific tricks. It was in seeing that this stuff is real, and that small teams are running it, and that the resulting workflow is calmer than the one they have today. Good signal for the next version of the talk. Less “here is the advanced pattern,” more “here is what a working setup actually looks like, and why the boring parts matter.”
Two questions worth writing down
Two of the questions during Q&A are still in my head, because the answers are the kind of thing I had not bothered to articulate before someone asked.
“Why skills and not just scripts?” This came up because half of what a skill ends up doing is “run a thing, parse the output, decide what to do next.” Which is what scripts do. So why the indirection?
The honest answer is that a script encodes one path. A skill encodes a capability: the description, the inputs it expects, the failure modes it knows about, the tools it composes. When something goes sideways (and at 50 tenants, something is always going sideways), a script gives up at the first unhandled case. A skill negotiates: it tries an alternate path, asks the operator for a confirmation, drops back to a fallback tool. The five-tier scaffolding around the skill is what makes that negotiation actually go somewhere instead of into a loop.
The TL;DR I gave at the meetup: scripts are great when the world is fixed. Skills earn their keep when the world is messy and you want the agent to keep going. (More on this in a follow-up.)
“MCP server or CLI tool?” This one I have a strong opinion on. I prefer CLIs.
Two reasons. First, every MCP roundtrip is tokens. Tool definitions, schemas, the wrapper boilerplate. It adds up fast on long tasks, and on a tenant onboarding the agent is spending most of its budget on glue, not on actually thinking about your problem. A python query_databricks.py "..." call is one tool invocation, one stdout, done. Specifically the Databricks SQL MCP is the one we kept reaching for, and the one a small query_databricks.py script replaces nicely. Second, CLIs degrade better. When the hosted MCP service has a hiccup mid-flow (which has happened to us in production), the agent that also knows how to invoke the local CLI finishes the job. The one that only knows the MCP gets stuck. So our preference is: build the CLI first, expose it as an MCP later if it earns the convenience tax.
I want to write up the MCP-vs-CLI argument properly, because it cuts against the default advice you’ll see, and it has cost-and-reliability evidence behind it. That’s on the queue.
The personal part
This was my first talk since before corona. Five-ish years of public-speaking rust. I had forgotten how much I miss the feeling of a real audience asking real questions, instead of typing into a void on LinkedIn.
What’s next
I am going to expand a few of the bits I had to cut from the slides into separate posts. The current shortlist:
- Knowledge scaffolding for AI agents. The five-tier pattern (data model → CLAUDE.md → rules → skills → tools) we use to make a coding agent productive in a real production codebase. This is the most stealable idea from the talk and the one I get the most questions about.
- Generator of generators. What
dabgenactually does, and why “the same Jinja template renders the bundle template and the bundle” turned out to be the right design. - MCP vs CLI: a token and reliability argument. The longer version of the answer above. Why we default to CLIs, when MCP is worth the cost, and what we measured.
- Tool-teaching beats prompt-engineering. When a hosted MCP drops mid-flow, the agent that also knows how to call your fallback Python script will finish the job. The one that just had a great prompt will not.
If you run a Databricks or AI engineering event in Europe and want a longer version of any of this, you can find me on LinkedIn.
The slides
Enjoy Reading This Article?
Here are some more articles you might like to read next: