Loving MOOCs
I am in love. Yes, I am really and deeply in love. I am in love with MOOCs :). But what are MOOCs? The term MOOC stand for massive open online course. According to the MOOC guide a MOOC is:
[…] a Massive Open Online Course. It is a gathering of participants, of people willing to jointly exchange knowledge and experiences for each of them to build upon.
Wikipedia defines it as:
an online course aiming at large-scale participation and open access via the web.
In other words, a MOOC is an online course aimed to a large audience, audience which interact not only with the tutors of a particular course, but also among themselves. I find that not only really cool but also amazing. Taking the same lecture with thousands of students from all over the world that most of the time are supportive and help you wherever you have a question.
I guess that although most of the readers of this blog are familiar with the term, I am sure that many have not taken one of these courses offered any of the MOOC websites. Therefore, I want to share my experiences and views as a user of these platforms.
So, what makes them different from watching some videos on YouTube or just reading the slides online? ( Or for that matter paying for some online tutorial/screencast). Here is what I found different and noteworthy:
- Interactive: many of the pre-existing online education sites offered recording of the lectures. Although of good quality, they cannot replace the one to one relationship that can be established when a single person is attending a lecture. Current MOOC use questions inside the videos (I would not dare to call this a 'interactive video'), allowing the user to double check if they are actually understanding the content the instructor is trying to explain. That somehow replaces the "in-class interaction" that one have when attending a real-world class room.
- Timed: these courses run during some fixed time. With this one I have love-hate relationship. I do like that these courses are timed, because it allows the university and instructor to commit to the teaching and also helps for them to know when a critical mass of student will be taking the class. For students, it is also helpful to know that they will be able to find people ready to answer their questions. The bad thing is that the homeworkers / exams are also held during this time span. Late submission generally decreases a lot the grade. So for a late starter it will be really hard to score a good grade or even get a certificate of accomplishment.
- this takes me to my next point: The courses are scored and sometimes you can get a certificate of completion. And sometimes even credits! For me the fact that you get grade / recognized for your work is one of the most important. Before that, I started courses of watched some videos on MIT OCW / YouTube, but as the time passed I eventually forgot that I was actually taking the class. Having some sort of recognition helps (at least me) to keep on track.
- Interactive (again): but I am not talking about the "video" this time but more about the fact they are forums where you can ask questions if some topic is clear enough or just give feedback. On this forums, no only other members of the "class" can answer but there also the equivalent of teaching assistants that generally answer quite fast to the students questions. In other opportunities when I watched some videos, e.g. In YouTube, I just have the comments. I once even dared to send an e-mail to a professor but of course, I received no answer :).
Currently there are many sites that offer MOOCs, being Coursera, Udacity and Edx the most popular (also free). There are also other courses that not necessarily use any of these sites, like the large scale machine learning course taught by Prof. Yann LeCunn and John Langford at NYU.
One characteristic that these platforms had was that most of the courses were in English and about most of them were about technical subjects, mostly related to computer science. Nowadays this is mo longer true. Today there are many non technical courses available, like music and history and courses in Spanish and French can also be found. Related to this, Coursera recently announced courses from more university worldwide adding more languages and topics to the offer, including my University and coincidentally my IDP evaluator Prof. Kleinsteuber.
I personally feel that I have not taken advantage of the existing course offering, most of the time this is due to timing issues. I have taken Introduction to Artificial Intelligence parts of Machine Learning, NLP and I have just finished completely the course Introduction to Sound Design. I am currently trying to follow course "Algorithm Design" but I started late due to my semester final exams and a 3 weeks trip through my country I had planned way in advance. I will try to finish it (although I will not receive any certificate) and try to attend the ones available in the future. There are many interesting upcoming course, I just hope I will have time and determination to finish it.
To conclude, I think there was no time before where the access to quality education material was as easy and free as today. I think that this is just the start, and step by step the classical classroom approach will be outdated, and it will start to shift into a more massive and collaborative approach to learning. I am not claiming now that MOOCs are going to replace the university experience completely, but this wills definitely affect it. To what extend it is yet to be seen.
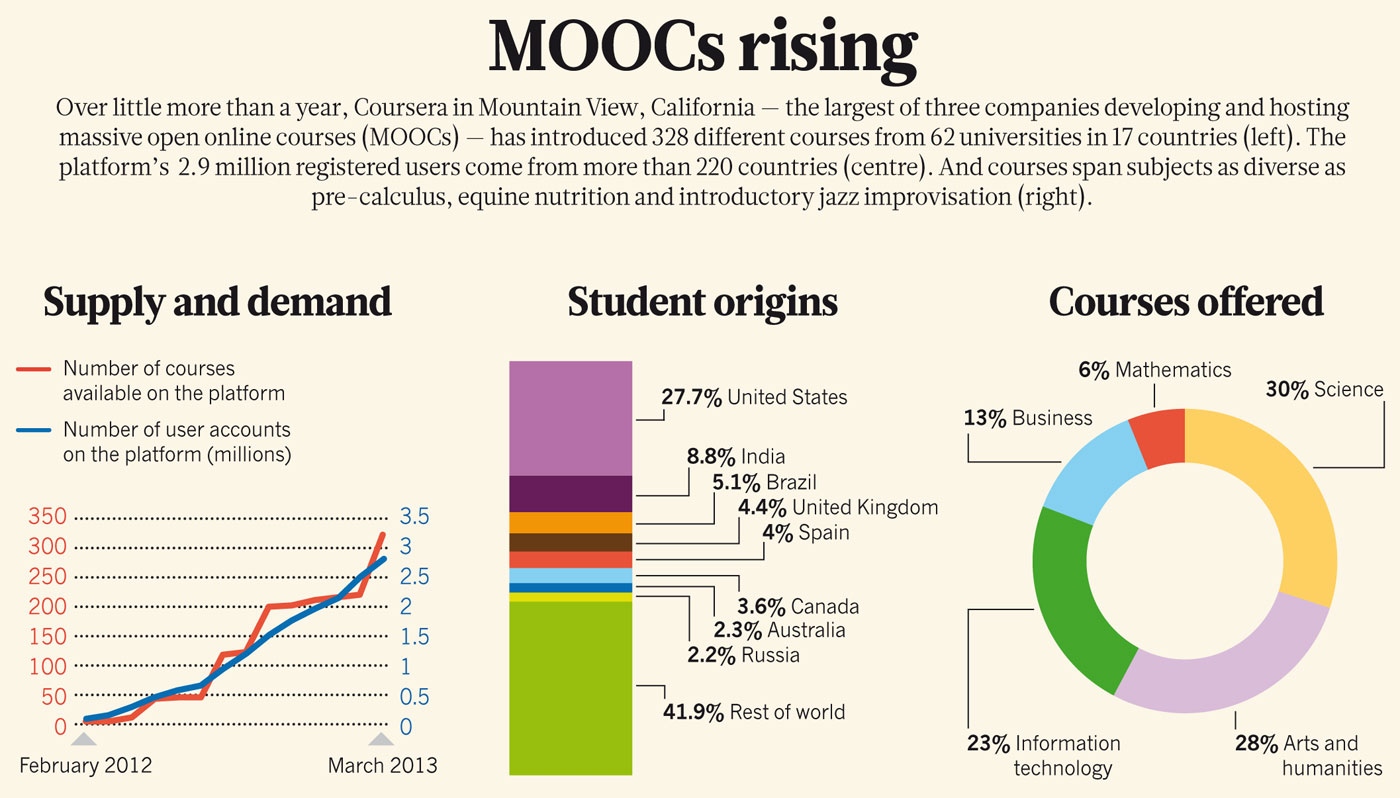
As a bonus, a nice graph showing interesting numbers. This graph comes from an article on the last issue of Nature on the impact of online learning / MOOCs on higher education: